
¿Y si pudieras probar tus campañas, productos o pricing sin gastar un solo euro en tráfico real?
¿Y si tus hipótesis pudieran ser validadas por miles de usuarios antes de que tu audiencia real las viera?
¿Y si mitigar el “cold start” dejara de ser un problema… incluso sin datos?
Todo eso ya no es una promesa futurista. Está ocurriendo. Y tiene nombre: usuarios (y datos) sintéticos.
Son réplicas digitales que simulan el comportamiento, decisiones e interacciones de usuarios reales. No son encuestas. No son datos estadísticos. Son gemelos digitales capaces de “vivir” experiencias de usuario completas, clic a clic, paso a paso, conversión a conversión.
Y no se limitan a observar: aprenden, reaccionan y evolucionan.
En el blog de AI Hackers profundizamos un poco más en las ventajas que nos aportan los usuarios sintéticos y algunos conceptos más generales. En el resto de este artículo nos centraremos en cómo podemos aprovechar estos usuarios y datos sintéticos en nuestras estrategias de Growth.
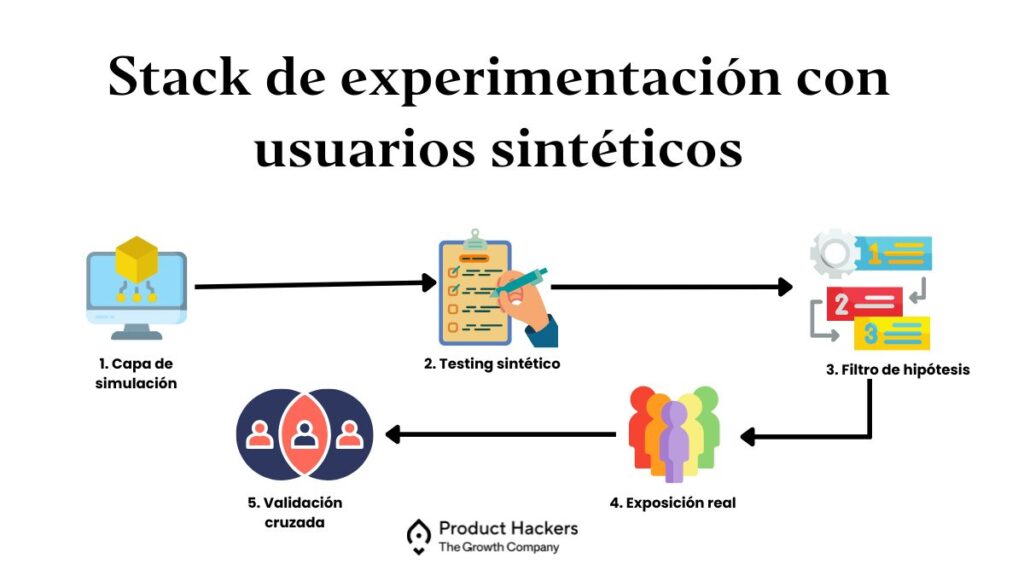
En Product Hackers trabajamos cada día diseñando ciclos de experimentación inteligentes. Hasta ahora, la única manera de validar una hipótesis era exponerla directamente a usuarios reales. Pero eso tiene fricción, coste y riesgo.
Con usuarios sintéticos, podemos cambiar el orden del proceso. Esta sería una arquitectura ideal:
Este nuevo stack acorta el ciclo de aprendizaje, reduce el desgaste del tráfico real y mejora la tasa de acierto desde el día uno.
Startups y eCommerce con bajo tráfico sufren un problema constante: no pueden experimentar con solidez. Sin datos, sin volumen, sin significancia estadística.
Pero los usuarios sintéticos permiten crear escenarios validados sin tráfico real, incluso antes de lanzar. Así, el producto, el pricing o la propuesta de valor llegan más afinados desde el minuto cero.
¿Cuándo merece la pena usar usuarios/datos sintéticos?
Existen múltiples formas de generar usuarios sintéticos, desde enfoques rule-based simples hasta modelos estadísticos tradicionales. Pero si queremos crear gemelos digitales que no solo imiten, sino que piensen, reaccionen y evolucionen, necesitamos un enfoque más robusto y dinámico. El más avanzado hoy en día se construye sobre tres pilares clave:
Todo gemelo sintético parte de un modelo. Y ese modelo, para ser útil, necesita comportamientos reales que sirvan como referencia. No hacen falta millones de datos ni una base completa: con una muestra representativa de sesiones, journeys o eventos, ya se puede modelar el comportamiento general de un tipo de usuario.
Estos datos permiten capturar patrones como:
Tiempos de decisión
Preferencias de navegación
Elasticidad al precio o fricción en el funnel
Eventos que disparan abandono o conversión
Importante: este paso se puede realizar sin almacenar datos personales (PII), y es compatible con una arquitectura privacy-first.
Una vez modelado el comportamiento base, necesitamos exponer al gemelo a múltiples escenarios. Aquí entra el Synthetic Data Vault: una herramienta que genera datos sintéticos “a medida” para simular condiciones específicas, como:
Altos picos de tráfico
Campañas ultra-agresivas
Cambios de producto no convencionales
Comportamientos anómalos o fraudulentos
Esto permite crear un entorno mucho más rico que el tráfico real, que rara vez contiene suficientes edge-cases para entrenar modelos sólidos. El Synthetic Data Vault actúa como una especie de simulador de posibilidades extremas.
Con los comportamientos modelados y los escenarios generados, el siguiente paso es permitir que el gemelo aprenda activamente por sí mismo. Aquí entra en juego el Reinforcement Learning (RL), un tipo de aprendizaje automático donde los agentes (en este caso, los usuarios sintéticos) reciben recompensas o castigos en función de sus decisiones.
Por ejemplo:
Si un gemelo “compra” tras una secuencia de pasos, recibe recompensa.
Si abandona el carrito o se frustra, recibe penalización.
Este mecanismo le permite no solo repetir comportamientos observados, sino descubrir nuevas estrategias que optimicen resultados, incluso en contextos nuevos o inciertos.
Igual que los coches de Fórmula 1 se prueban en simuladores antes de tocar el circuito, nuestros productos, campañas y procesos también deberían vivir su primera vuelta en entornos sintéticos.
¿La alternativa? Probar con tu tráfico real, con tus usuarios reales, con tus ingresos reales…
y cruzar los dedos.
En un mercado donde la velocidad importa, pero el coste del error es altísimo, los Synthetic Users representan una capa de inteligencia anticipada.
No vienen a sustituir la realidad. Vienen a hacerla más segura, rápida y eficaz. Si no estás simulando antes de lanzar, estás corriendo con los ojos cerrados.






