
El marketing moderno vive inmerso en una paradoja que marca una época sin precedentes: disponemos de más datos que nunca, pero tomar decisiones realmente efectivas nunca ha sido tan complejo. Por eso la pregunta es evidente: ¿qué debemos hacer para liderar el marketing en tiempos de IA?
Vivimos bajo una exigencia constante de justificar cada euro invertido, precisamente en un contexto donde las señales claras se diluyen, los identificadores se desvanecen y las capas de modelos predictivos alejan cada vez más al marketer de la observación directa del comportamiento real.
En este escenario, entender el desafío de la medición va mucho más allá de recopilar datos; se trata de mejorar radicalmente nuestra capacidad para tomar decisiones estratégicas acertadas. Porque el reto no es medir, es decidir mejor.
En este artículo nos adentraremos en tres grandes fuerzas transformadoras que redefinen cómo entendemos, aplicamos y aprovechamos la medición en marketing:
1. La erosión de los datos observables: ¿Cómo podemos navegar en un entorno marcado por regulaciones estrictas de privacidad y restricciones crecientes en la recopilación directa de datos?
2. La automatización inteligente y sus límites humanos: La inteligencia artificial, el machine learning y la analítica avanzada ofrecen capacidades nunca antes vistas para analizar grandes volúmenes de datos y descubrir patrones ocultos.
3. El imperativo estratégico de la medición como ventaja competitiva: La medición ya no puede ser vista solo como un mecanismo reactivo de control y validación, sino como un activo estratégico decisivo que impulsa la diferenciación y el crecimiento sostenible. Definiremos por qué las marcas que dominen una estrategia de medición robusta y proactiva tendrán una ventaja competitiva prácticamente insuperable.
El objetivo de este artículo es ayudarte a transformar la medición desde un ejercicio reactivo y secundario, hacia una auténtica palanca estratégica capaz de anticiparse, influir y sostener el crecimiento de tu negocio.
Durante años hemos vivido como la medición en marketing ha estado dominada por la elaboración de informes reactivos, centrados en métricas superficiales y fácilmente obtenibles. Estos informes cumplían una función esencialmente informativa, permitiendo justificar presupuestos y mostrar resultados generales, pero muy pocas veces impulsaban decisiones estratégicas reales o cambios sustanciales en el rumbo del negocio.
Hoy, este paradigma está cambiando radicalmente. En un entorno donde cada inversión debe demostrar valor tangible, la medición ha dejado de ser una tarea pasiva para convertirse en un proceso dinámico y orientado a la acción.
Ya no basta con recopilar números y crear dashboards; las marcas líderes necesitan interpretar activamente esos datos para descubrir dónde reside el auténtico impacto estratégico, y cómo maximizar el valor incremental de cada acción.
Este cambio implica una profunda transformación mental: pasar del enfoque puramente cuantitativo al cualitativo-estratégico, entender la medición no como fin, sino como medio. La nueva mentalidad de medición exige mirar más allá del dato superficial, identificar el valor marginal de cada inversión, y priorizar decisiones que generen un impacto real y medible en el crecimiento del negocio.
En el marketing tradicional, la métrica del Retorno de la Inversión (ROI), así como sus derivadas como pueda ser el ROAS, han sido durante mucho tiempo el estándar principal para evaluar la eficacia de las acciones que realizamos.
Sin embargo, en un entorno altamente competitivo y en constante evolución, la pregunta clave ya no es simplemente si el ROI es positivo, sino si estamos extrayendo el máximo valor posible de cada euro invertido.
Aquí entra en juego el concepto emergente de “Marginal ROI Optimization” u «Optimización del Retorno Marginal», que redefine completamente la conversación con los CFOs y los C-level. Este enfoque supera la simple justificación de las inversiones realizadas y se centra en optimizar su asignación para alcanzar el mayor retorno incremental posible.
No basta con demostrar un retorno positivo; ahora es imperativo identificar en qué punto específico cada euro adicional invertido genera menos valor, permitiendo tomar decisiones de asignación mucho más estratégicas y rentables.
Para profundizar en este concepto, tenemos frameworks avanzados como las curvas de retornos decrecientes («diminishing returns curves») y las curvas en S (S-Curves).
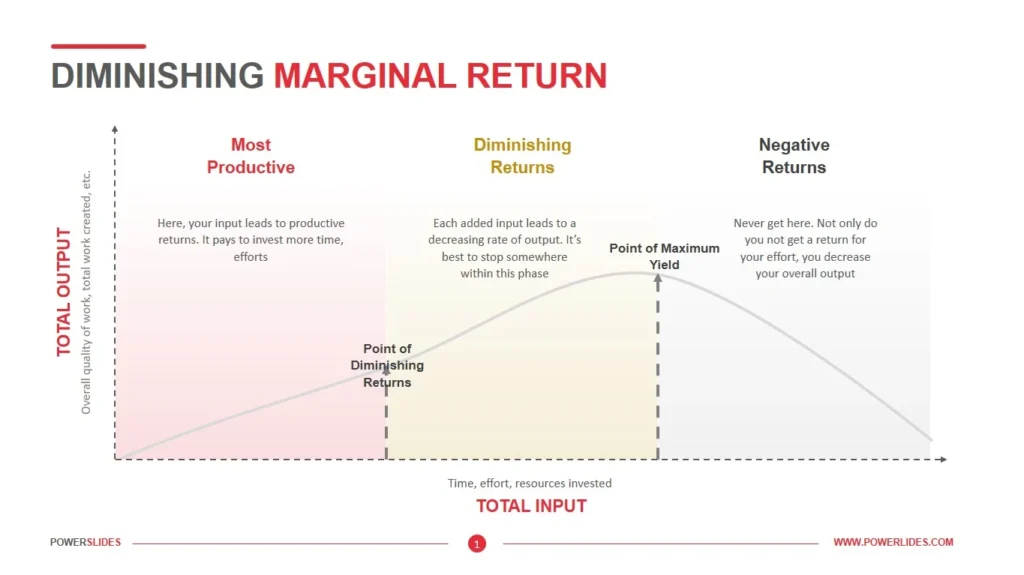
Utilizando simulaciones basadas en datos históricos y modelos predictivos, las marcas pueden anticipar estos comportamientos, visualizar los puntos de inflexión y redistribuir sus presupuestos para maximizar el impacto global. Esta es la clave de la nueva mentalidad: pasar del ROI como foto estática, al ROI marginal como brújula dinámica del crecimiento.
Otra de las grandes peleas diarias que hemos vivido los marketers es la medición de la atribución directa: ¿qué canal trajo qué conversión? Esta visión, aunque útil para optimizar el corto plazo, ignora una verdad crucial: el marketing actúa también de forma acumulativa, construyendo percepción, recuerdo, confianza y preferencia con el paso del tiempo.
La clave está en pasar de medir el rendimiento inmediato a comprender el impacto acumulado que nuestras acciones generan a lo largo de múltiples puntos de contacto y periodos prolongados.
Por ejemplo, un anuncio de televisión puede no generar una conversión directa, pero al verse repetidamente en distintas fases del funnel y en combinación con otras acciones, puede aumentar significativamente la probabilidad de conversión futura. Este efecto acumulativo y sinérgico entre canales y mensajes es lo que muchos modelos tradicionales de atribución no capturan adecuadamente.
Una herramienta que comienza a captar esta complejidad es el Brand Lift Study, que mide el cambio en variables de percepción como el reconocimiento, la consideración o la intención de compra tras una exposición publicitaria.
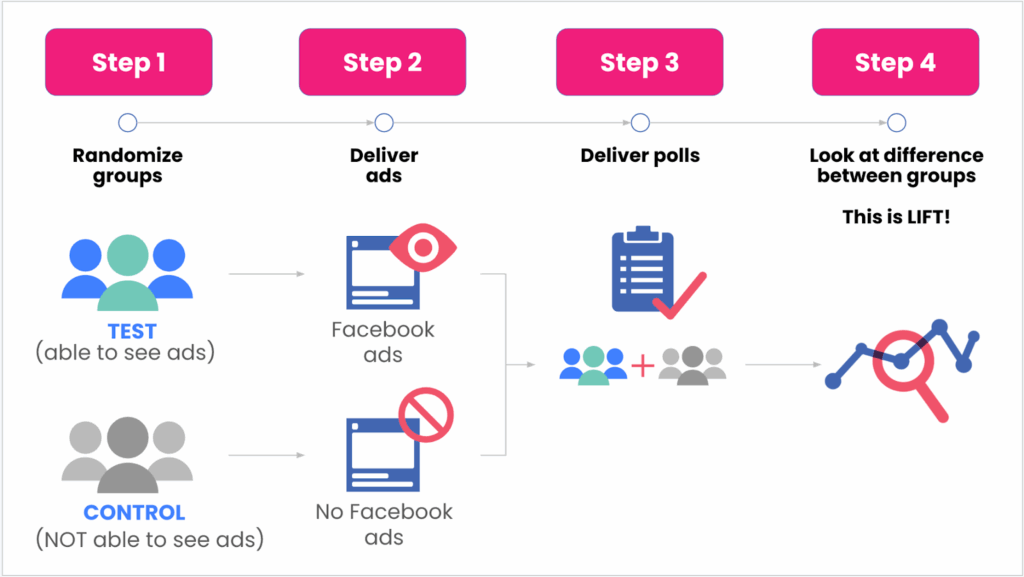
Pero incluso estos estudios se quedan cortos si no entendemos el fenómeno de los “stacked effects” o efectos apilados: la acumulación progresiva de impactos que se refuerzan entre sí en el tiempo, como lo hacen los modelos de Mix de Marketing (MMMs). Estos modelos, cuando están bien construidos, permiten observar cómo el efecto de una campaña no es aislado, sino que contribuye a una curva de crecimiento sostenido o, en algunos casos, a efectos rezagados (lagged impact) que se manifiestan semanas o meses después de la inversión inicial.
Por ejemplo, una campaña de branding en medios masivos puede no generar picos inmediatos de ventas, pero sí aumentar la efectividad de las campañas de performance que se ejecutan posteriormente, reduciendo su coste por adquisición (CPA) gracias al mayor reconocimiento de marca. O en el caso de una marca nueva, se puede observar que las búsquedas de marca y el tráfico orgánico aumentan gradualmente tras varios ciclos de exposición publicitaria, sin que ninguna acción individual pueda atribuirse todo el mérito.
Cuantificar este tipo de impacto acumulado requiere una combinación de enfoques: desde el uso de modelos estadísticos multivariables (como los MMMs), hasta el seguimiento de indicadores de equity de marca en el tiempo. Esto implica una visión más holística y paciente del marketing, donde se valora no solo lo que convierte hoy, sino lo que construye una marca sólida y preferida en el largo plazo.
Las innovaciones tecnológicas están redefiniendo profundamente las capacidades de los equipos de marketing. Pasamos de herramientas que meramente reportaban datos a sistemas inteligentes que ayudan a entender, predecir y actuar.
La clave ahora no es solo tener datos, sino tener poder para transformarlos en decisiones más ágiles, contextuales y estratégicas.
La Inteligencia Artificial ha evolucionado rápidamente de una herramienta de análisis asistido a un sistema que puede diagnosticar, actuar y aprender casi en tiempo real. Esta transformación está redefiniendo el rol del marketero moderno, quien ahora debe combinar pensamiento estratégico con una comprensión operativa de sistemas cada vez más autónomos e inteligentes.
Modelos como GPT pueden clasificar comentarios por temas, identificar patrones emergentes y detectar cambios sutiles en el tono del feedback. También permiten a los equipos anticipar puntos de fricción del usuario sin esperar a que se reflejen en las métricas cuantitativas. Asimismo, puede ser entrenado para detectar anomalías en campañas: si el engagement de una audiencia clave cae inesperadamente, el modelo puede lanzar una alerta y sugerir hipótesis sobre la causa.
Sin embargo, estas capacidades no están exentas de riesgos. Las «alucinaciones» y los sesgos heredados de los datos de entrenamiento pueden llevar a conclusiones erróneas. Por eso es crucial adoptar un enfoque de supervisión conocido como «human-in-the-loop«, donde la IA actúa como generadora de hipótesis y aceleradora de análisis, pero la validación crítica recae en humanos.
A medida que las capacidades de los modelos se vuelven más sofisticadas, el marketing entra en una era de agentes autónomos: sistemas capaces de diagnosticar desviaciones, ejecutar acciones correctivas y aprender de sus propias intervenciones. Esto habilita lo que se conoce como feedback loops cerrados, donde los datos fluyen, se interpretan y se actúa sobre ellos en ciclos cada vez más cortos.
Un ejemplo concreto: un sistema detecta un aumento del CPA en una campaña de captación, identifica que el problema está en un segmento geográfico concreto con baja conversión, reduce la inversión automáticamente en ese segmento y redirige el presupuesto hacia audiencias con mejor performance. Todo esto puede ocurrir sin intervención humana.
Así emergen las «self-healing campaigns», campañas que se ajustan de forma dinámica según lo que aprenden en tiempo real. No solo reaccionan: también documentan los cambios, analizan resultados y refinan sus parámetros futuros. Este tipo de campañas requieren una base sólida de datos, reglas claras y una capacidad de ejecución automatizada.
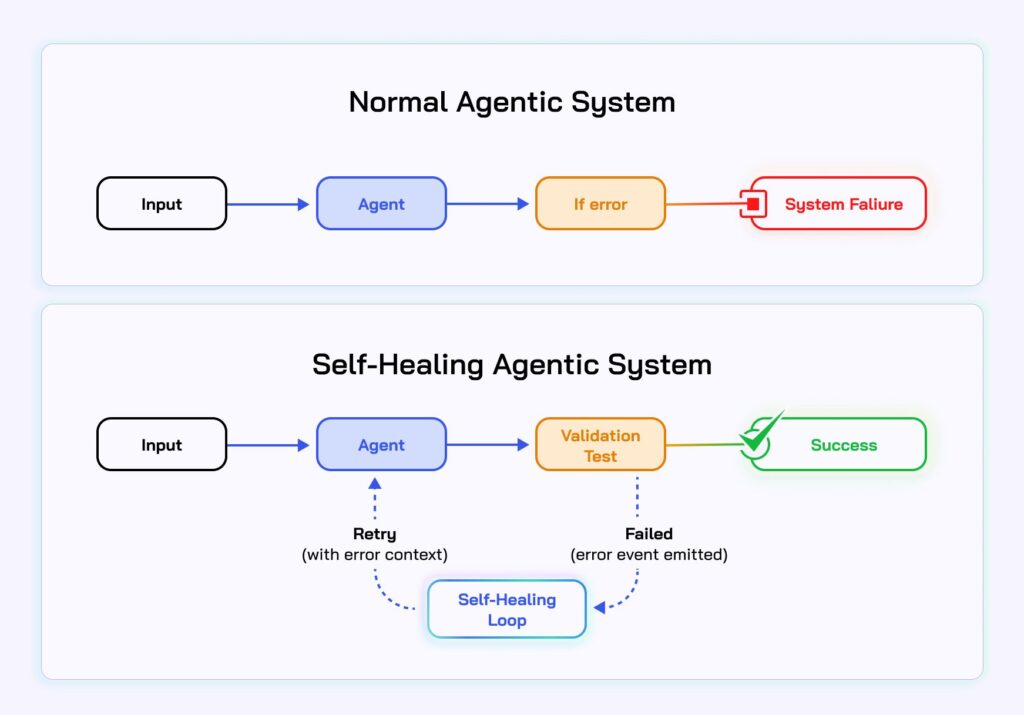
La autonomía conlleva poder, pero también riesgo. ¿Qué ocurre si un sistema malinterpreta los datos y genera decisiones en cascada que afectan negativamente el rendimiento? Para evitar este escenario, es necesario establecer mecanismos de control: umbrales de intervención humana, validaciones cruzadas, entornos de prueba aislados, y sistemas de alerta.
Además, la responsabilidad algorítmica es clave. Las organizaciones deben asegurar trazabilidad sobre qué decisiones fueron automatizadas, bajo qué criterios, y con qué resultados. Solo así se puede mantener la confianza en un sistema que toma decisiones por sí mismo.
Por más sofisticado que sea un modelo, el juicio estratégico sigue siendo un activo irremplazable. Los algoritmos pueden analizar el pasado y proyectar el futuro, pero no siempre comprenden los matices del presente. Aquí entra en juego un concepto revelador: la “insulting recommendation”. Es decir, cuando un modelo propone una acción tan obvia, genérica o irrelevante que insulta la inteligencia del analista o demuestra una falta total de contexto.
Este tipo de señales no debe verse como fallos, sino como oportunidades de mejora: indican que el modelo necesita más datos, más contexto o una reevaluación de su lógica. Para gestionar esta realidad, debemos entender dos grandes bloques: tareas automatizadas donde la IA tiene ventaja (procesamiento masivo, detección de patrones, optimización de variables), combinadas con la supervisión humana en decisiones estratégicas, interpretación de contexto, resolución de ambigüedades o gestión de riesgos.
El marketing del futuro no es humano o máquina. Es humano con máquina. La colaboración entre ambos no sólo multiplica la eficiencia, sino que eleva la calidad y profundidad de las decisiones tomadas. Entender bien este equilibrio será una ventaja competitiva difícil de igualar.
La precisión, consistencia y utilidad de la medición en marketing no dependen únicamente de las herramientas analíticas o los dashboards, sino de algo más fundamental: la arquitectura de datos sobre la que se apoya todo el sistema.
Una estrategia de medición moderna exige una infraestructura de datos sólida, flexible e interoperable, capaz de adaptarse a múltiples fuentes, canales y dispositivos sin generar fricciones.
Una arquitectura débil genera datos inconsistentes, métricas contradictorias y decisiones erróneas. En cambio, una arquitectura bien diseñada permite escalar la medición, activar insights en tiempo real y conectar acciones de marketing con resultados de negocio de forma confiable.
Imagina una empresa que lanza un nuevo producto. Puede usar un stack compuesto por Segment (para la recolección de eventos), un data layer unificado (para asegurar consistencia entre frontend y backend), BigQuery (para almacenamiento y análisis), y Looker o Power BI para visualizar los resultados. Esta arquitectura permite comparar el rendimiento del funnel por canal, detectar puntos de fuga y activar mensajes personalizados en función del comportamiento observado.
En la era del marketing omnicanal, una buena arquitectura de datos no es opcional: es la base sobre la que se construye todo lo demás.
Las organizaciones han invertido en sistemas de analítica para comprender mejor su rendimiento, pero demasiadas veces los datos se han quedado en dashboards, informes o presentaciones.
La verdadera ventaja competitiva no está en saber más, sino en actuar más rápido y mejor a partir de lo que se sabe. Este es el «último kilómetro» de la medición: el momento en que el insight se convierte en decisión, y la decisión en acción.
Una de las principales razones por las que muchas organizaciones no activan sus datos es la separación estructural entre quienes analizan y quienes ejecutan. El equipo de analítica identifica una anomalía, pero tarda días en escalarla. El equipo de medios recibe un informe semanal, pero la campaña ya está en otro punto. El ecommerce detecta un patrón, pero no tiene cómo personalizar la experiencia en tiempo real.
Eliminar esa fricción implica conectar los sistemas de análisis con los sistemas de ejecución. Y eso exige tanto una arquitectura técnica adecuada como un diseño organizativo que fomente la acción.
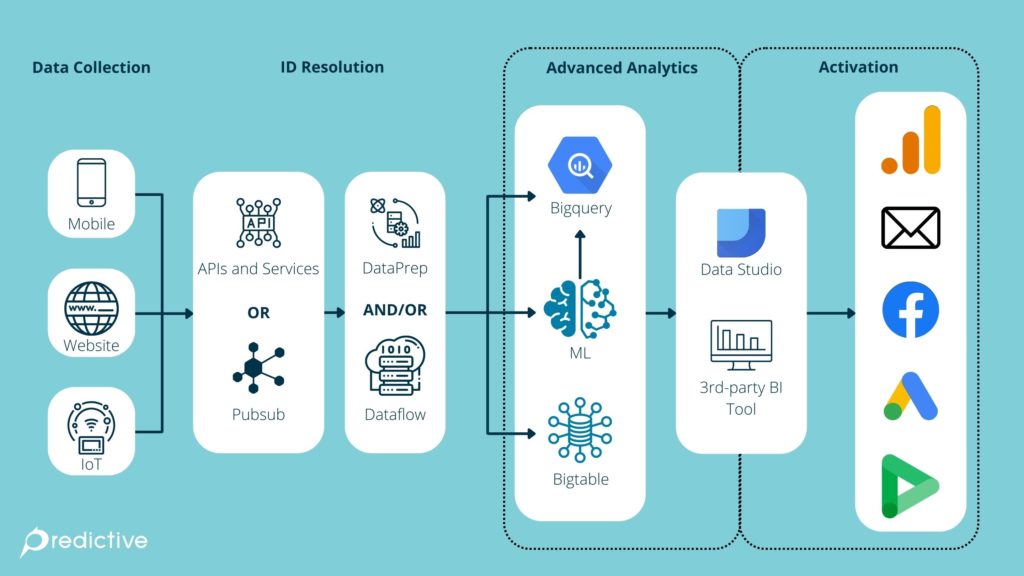
La irrupción de herramientas como los CDPs (Customer Data Platforms) ha abierto nuevas posibilidades para activar insights en tiempo real. Plataformas como Segment, Bloomreach, mParticle o Salesforce CDP permiten unificar datos de múltiples fuentes (comportamiento en web, campañas, CRM, eventos de producto) en perfiles dinámicos que pueden usarse para tomar decisiones automatizadas.
Por ejemplo:
La clave está en construir workflows automatizados que respondan a condiciones de negocio definidas previamente. No es solo recopilar datos, sino diseñar reglas que digan: «Si pasa esto, haz aquello».
Los dashboards no deben ser un punto final, sino una superficie de activación. Por eso, cada vez más organizaciones están integrando sus sistemas de visualización (como Looker, Tableau o Power BI) con herramientas de ejecución como CRMs, plataformas de automatización de marketing o sistemas de recomendación en producto.
Esto permite pasar de insights pasivos a acciones automáticas o semiautomáticas:
Este tipo de integración requiere gobernanza, seguridad y claridad en los triggers, pero marca la diferencia entre ver los datos y vivir los datos.
Medir bien es empezar. Actuar bien, en tiempo real, es ganar.
La era de la observación directa ha quedado atrás. Con el auge de las regulaciones de privacidad, la desaparición de cookies de terceros y la creciente fragmentación de los canales, los equipos de marketing ya no pueden depender exclusivamente de señales individuales claras y deterministas para medir el comportamiento del consumidor.
En su lugar, el futuro de la medición se apoya en modelos probabilísticos y técnicas de inferencia inteligente que reconstruyen la realidad a partir de patrones, datos agregados y cohortes representativas.
En este nuevo paradigma, la observación directa es sustituida por modelos de inferencia responsables. Ya no se trata de saber con certeza qué usuario hizo clic o compró, sino de estimar con solidez qué comportamientos se están produciendo a nivel agregado y cómo las campañas están influyendo en ellos.
Los modelos de inferencia suelen construirse a partir de datos de cohortes consentidas (usuarios que han aceptado compartir sus datos) y se combinan con fuentes agregadas como datos de campañas, tráfico web, y métricas de conversión. Por ejemplo, si ya no podemos rastrear la actividad de cada usuario en un funnel, sí podemos analizar cómo se comporta una cohorte con características similares bajo ciertas condiciones de exposición.
Esta lógica se asemeja más a la ciencia estadística que a la trazabilidad absoluta. La clave está en construir inferencias robustas, bien calibradas y éticamente responsables. La validación cruzada se vuelve fundamental: dividir los datos en subconjuntos de entrenamiento y prueba para comprobar si el modelo es capaz de predecir lo que sucede en escenarios no vistos. También se deben establecer benchmarks de precisión estimada, aceptando un margen de error controlado y comprendiendo los límites reales de los modelos.
Un ejemplo práctico es el caso de una marca que, al no poder medir individualmente la atribución de sus campañas de display, crea un modelo de inferencia basado en usuarios logueados, actividad por canal, y comportamiento histórico de cohortes similares. El modelo estima el impacto con un 85% de precisión validada, lo que permite tomar decisiones informadas incluso en ausencia de trazabilidad completa.
En este contexto, la confianza no se construye con certezas absolutas, sino con transparencia sobre los supuestos del modelo, sus márgenes de error y sus capacidades predictivas. Medir ya no es ver directamente, sino saber interpretar bien lo que se intuye.
En un mundo donde las señales individuales desaparecen progresivamente por restricciones de privacidad o cambios tecnológicos (como el fin de las cookies o el tracking en iOS), medir incrementalidad se vuelve una de las formas más sólidas de entender si una acción de marketing ha generado un impacto real.
La incrementalidad no busca saber «quién hizo clic», sino responder una pregunta más potente: ¿qué habría pasado si no hubiéramos hecho esta acción?
Ejemplo: una cadena de supermercados lanza una campaña de TV solo en ciertas provincias. Si las ventas crecen un 12% en las zonas tratadas y solo un 3% en las de control, se puede atribuir un lift neto del 9% a la campaña.
Ejemplo: de una base de 100.000 usuarios, 90.000 reciben un email con una promoción y 10.000 no. Si el grupo tratado convierte un 2,1% y el holdout un 1,6%, se estima una mejora del 0,5 puntos porcentuales atribuible al email.
Estas soluciones permiten tomar decisiones presupuestarias no en base a atribución directa, sino a valor incremental comprobado. En un entorno sin trazabilidad individual, esta es una de las pocas verdades operativas que quedan.
Cuando no se puede acceder a datos reales de usuario (por privacidad, regulación o simplemente porque no existen), los datos sintéticos y las simulaciones ofrecen una alternativa poderosa y ética para modelar el comportamiento del mercado.
Los datos sintéticos no representan individuos reales, sino que son generados artificialmente a partir de patrones estadísticos observados. Esto permite crear entornos de prueba y modelado que respetan la privacidad y al mismo tiempo capturan la lógica del sistema. Los podemos crear:
Imagina que una marca está considerando lanzar una promoción agresiva de 2×1 en su ecommerce. Sin datos individuales para predecir el impacto en márgenes o canibalización de otras categorías, decide usar datos sintéticos para modelar diferentes escenarios. Gracias a ello, puede anticipar que el descuento atraerá nuevos usuarios, pero reducirá significativamente el AOV (Average Order Value), lo cual cambia su enfoque antes de llevarlo a producción.
En otro caso, un equipo de medios desea entender cómo se comportaría su modelo de asignación presupuestaria si redistribuyera parte de su inversión de televisión a canales digitales. Sin necesidad de tocar una sola campaña real, pueden simular el resultado con datos sintéticos basados en su histórico de rendimiento y estimar impactos antes de arriesgar el presupuesto.
Este enfoque también es útil para construir y entrenar modelos predictivos de negocio como la probabilidad de abandono (churn), el lifetime value (LTV) o la propensión a comprar cierto producto, incluso antes de haber acumulado suficientes datos reales. Esto permite desplegar estrategias proactivas desde el primer momento en mercados nuevos o en fases tempranas del ciclo de vida del cliente.
Incluso en entornos creativos, como el diseño de journeys personalizados, se pueden testear variaciones de mensajes, canales o secuencias de interacción en un entorno sandbox que replica comportamientos esperados sin exponer a usuarios reales ni afectar KPIs actuales.
El uso de datos sintéticos y simulaciones trae consigo tres ventajas cruciales. En primer lugar, cumple con los estándares más estrictos de privacidad, como GDPR o CCPA, ya que no involucra datos reales de usuarios.
En segundo lugar, acelera el aprendizaje, al permitir iterar, probar y ajustar sin depender del volumen de tráfico real ni de largos periodos de observación. Y finalmente, habilita la experimentación sin consecuencias reales, lo que permite explorar ideas audaces, testar hipótesis complejas o construir nuevas estrategias sin riesgo operativo o reputacional.
En la era del marketing basado en evidencia, medir no es suficiente: hay que aprender.
Las organizaciones que integran la medición como parte de un ciclo continuo de aprendizaje, validación y adaptación son las que transforman los datos en decisiones que generan crecimiento sostenido.
Este nuevo enfoque convierte al área de medición en un motor de evolución estratégica, no en un mero reflejo del pasado.
Uno de los grandes desafíos en las organizaciones que experimentan de forma constante es evitar que el conocimiento generado se diluya con el tiempo o quede atrapado en silos.
A menudo, se invierte en pruebas, se generan insights valiosos, y sin embargo se repite el mismo test meses después, se vuelve a plantear la misma hipótesis o se desconoce lo que ya se había aprendido en otro equipo. Esto tiene un coste invisible pero profundo: la deuda de aprendizaje (learning debt).
La learning debt es el conocimiento que deberías tener acumulado pero que no documentaste, compartiste ni consolidaste. Como la deuda técnica, crece con el tiempo y penaliza la velocidad futura de aprendizaje. Cuanto mayor es, más tiempo se invierte en redescubrir lo que ya se sabía. La solución es construir un sistema de documentación del aprendizaje que convierta cada experimento en un activo reutilizable por toda la organización.
Un buen sistema no se limita a almacenar reportes; debe estructurar el conocimiento para facilitar la reutilización. Cada test documentado debería incluir:
Desde Product Hackers, desarrollamos eXperimentor precisamente para atacar este problema. Nuestra plataforma no solo permite diseñar, ejecutar y seguir la trazabilidad de los experimentos, sino que convierte cada test en una ficha de conocimiento reutilizable. Cada hipótesis validada (o no) alimenta una base de aprendizaje accesible por todo el equipo, con filtros por cliente, canal, métrica o resultado.
Además, gracias al sistema de recomendaciones cruzadas, eXperimentor sugiere hipótesis validadas en contextos similares, acelerando el diseño de nuevos tests y evitando la repetición innecesaria. Así, el aprendizaje se convierte en un sistema compuesto, donde cada test nuevo se apoya sobre lo que ya se sabe, y no parte de cero.
La madurez de una organización que aprende no se mide solo por cuántos tests ejecuta, sino por cuánta inteligencia acumula con cada uno. Un buen repositorio de aprendizajes es como una memoria colectiva: permite que el conocimiento sobreviva al paso del tiempo, los cambios de equipo o las prioridades fluctuantes.
En tiempos donde la capacidad de adaptación lo es todo, documentar bien lo aprendido no es un lujo. Es una inversión en velocidad futura.
Muchos equipos de marketing realizan experimentos, pero pocos lo hacen con una agenda clara de aprendizaje. En lugar de acumular tests aislados que optimizan detalles tácticos, las organizaciones más avanzadas trabajan con Learning Agendas: estructuras formales que definen las hipótesis estratégicas clave que deben validarse para avanzar en el negocio.
Una Learning Agenda parte de preguntas fundamentales: ¿Qué palancas realmente aceleran el crecimiento? ¿Qué mensajes generan mayor percepción de valor? ¿Qué canales maximizan la eficiencia en distintos estadios del funnel? Estas preguntas no se responden con curiosidad suelta, sino con diseños experimentales rigurosos, priorizados según impacto potencial y viabilidad.
Por ejemplo, en lugar de testear variaciones de color en un CTA, una empresa puede establecer como hipótesis estratégica que los mensajes de impacto social elevan la conversión en nuevos segmentos. A partir de allí, se diseñan múltiples experimentos coordinados en distintos puntos de contacto y canales. El valor no está solo en ganar más clics, sino en descubrir verdades replicables que informen decisiones futuras de inversión, producto y comunicación.
Además, una agenda de aprendizaje bien ejecutada permite documentar lo aprendido, compartirlo transversalmente y evitar la repetición de errores o tests redundantes. Se convierte en un activo intelectual de la compañía.
Vivimos en un entorno donde cada vez más decisiones de compra se toman en espacios difíciles de rastrear: grupos privados, comunidades cerradas, conversaciones en apps de mensajería o recomendaciones de influencers que no generan clics directos. Sin embargo, que algo no se pueda medir directamente no significa que no tenga un impacto profundo. El reto está en diseñar estrategias de medición indirecta que capten ese rastro invisible.
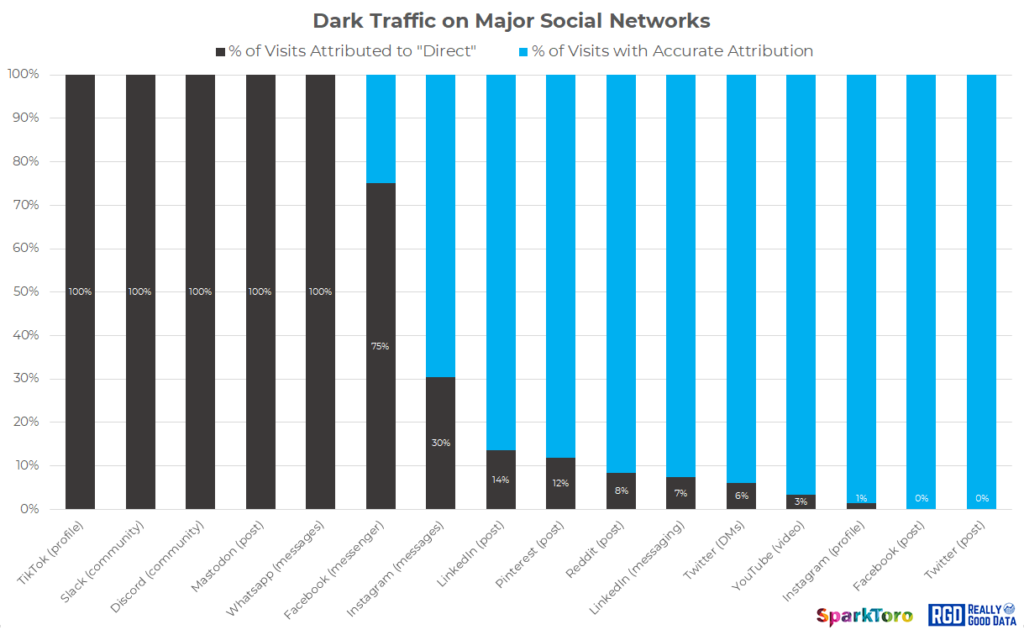
Una de las tácticas más potentes es observar las búsquedas de marca (branded search). Si tras una colaboración con un influencer o una aparición en un podcast se incrementa significativamente el volumen de búsquedas con tu marca como término principal, es una señal clara de que algo movió la aguja, incluso si no puedes rastrear un clic.
Otra estrategia es la implementación de paneles cualitativos, donde se entrevista o encuesta regularmente a una muestra representativa de consumidores para detectar el impacto de acciones de marketing no trazables digitalmente. Asimismo, los códigos embebidos (por ejemplo, cupones únicos compartidos por canal) permiten establecer conexiones causales en entornos donde no hay cookies o parámetros UTM.
Por último, el análisis de menciones en el dark social (a través de tecnologías de escucha social o detección de referencias en foros, Discords, newsletters o Slack communities) permite identificar patrones de impacto cualitativo que pueden incorporarse a los modelos de atribución más amplios.
El secreto está en combinar lo cuantitativo con lo cualitativo, lo visible con lo inferido, para obtener una imagen completa del verdadero alcance de tus acciones en canales emergentes.
El poder de medir con precisión implica también una gran responsabilidad. A medida que los modelos se vuelven más sofisticados y la capacidad de modelar el comportamiento del usuario aumenta, surgen preguntas éticas ineludibles: ¿Hasta qué punto podemos y debemos hacerlo? ¿Dónde trazamos la línea entre lo aceptable y lo invasivo?
Uno de los dilemas clave es el del consentimiento del usuario: muchos sistemas aún operan con una comprensión ambigua o poco transparente de lo que el usuario ha aceptado realmente. A esto se suma el uso creciente de dark patterns, interfaces diseñadas para manipular el comportamiento del usuario bajo el pretexto de mejorar la conversión. Estas prácticas erosionan la confianza y generan un terreno éticamente cuestionable.
Otro reto es la transparencia en los modelos predictivos. Cuando una decisión algorítmica impacta qué contenido ve un usuario, qué anuncio recibe o incluso qué precio se le muestra, es esencial comprender y poder explicar cómo y por qué se tomó esa decisión. De lo contrario, entramos en un terreno opaco con posibles consecuencias sociales, legales y reputacionales.

Para guiar una medición responsable, es fundamental apoyarse en marcos éticos sólidos como los propuestos por la WFA (World Federation of Advertisers), que recomiendan principios como la proporcionalidad, la transparencia, la explicabilidad y el respeto por la autonomía del consumidor. Incluir estos principios no como un anexo legal, sino como parte integral del diseño de sistemas y estrategias de medición, será lo que distinga a las organizaciones verdaderamente sostenibles en el tiempo.
En esta nueva era del marketing, la búsqueda de una única fuente de verdad se revela insuficiente. El entorno es demasiado fragmentado, volátil y opaco como para depender de una sola métrica, un único dashboard o una sola metodología.
La clave ya no es perseguir la certeza absoluta, sino construir un sistema confiable que nos permita navegar con solidez en medio de la incertidumbre.
Este sistema se compone de múltiples elementos interconectados:
Pero, sobre todo, requiere un liderazgo valiente, capaz de tomar decisiones imperfectas basadas en evidencia imperfecta, y convertirlas en acciones consistentes.
Medir ya no es solo observar. Es anticipar. Es construir modelos mentales compartidos. Es validar hipótesis estratégicas. Es aprender más rápido que la competencia. Y, en última instancia, es crecer.
Por eso en este artículo no hemos propuesto respuestas, sino 12 principios que pueden ayudarte a pensar, estructurar y evolucionar tu enfoque de medición para que deje de ser una función periférica y se convierta en el corazón estratégico del marketing moderno.
Porque, como toda ventaja competitiva real, medir bien no es una función: es una mentalidad.
Y en la era de la inteligencia artificial, de los datos difusos y los usuarios invisibles, quienes midan con mayor inteligencia, serán quienes lideren el crecimiento.
Es momento de pasar de la métrica… al impacto.






