
En un post anterior ya hablé sobre cómo experimentamos en los equipos de Growth y que, a modo de resumen, la experimentación consiste en la aplicación del método científico para validar cómo de probable es que exista causa-efecto entre nuestra acción y el resultado obtenido. Pero la experimentación solo habla de la ejecución, un equipo de Growth hace muchas otras cosas.
Esta imagen lo representa bien:

Básicamente, un equipo de Growth pasa por la lente de un microscopio (Data Analytics) a un organismo tan complejo como lo es un negocio, para entender, priorizar y ejecutar acciones (experimentos) capaces de mover los engranajes internos del sistema (producto), el entorno donde se encuentra (marketing) o el propio sistema en sí (modelo de negocio); con el objetivo de hacer que los átomos (métricas) y estructuras más complejas (objetivos clave) crezcan en número (expansión) o en tamaño (volumen).
Dicho así puede parecer complejo, por eso es importante que pensemos en la experimentación como un framework de trabajo. Un proceso iterativo que se sirve así mismo para obtener respuestas e incorporarlas al primer punto de análisis. Un proceso que, como objetivo propio, busca agilizar la velocidad con la que se cumple el ciclo para aumentar la velocidad de aprendizaje, que es el objetivo último de la experimentación.
Veámoslo en imagen para que se entienda por qué fases pasa este proceso:
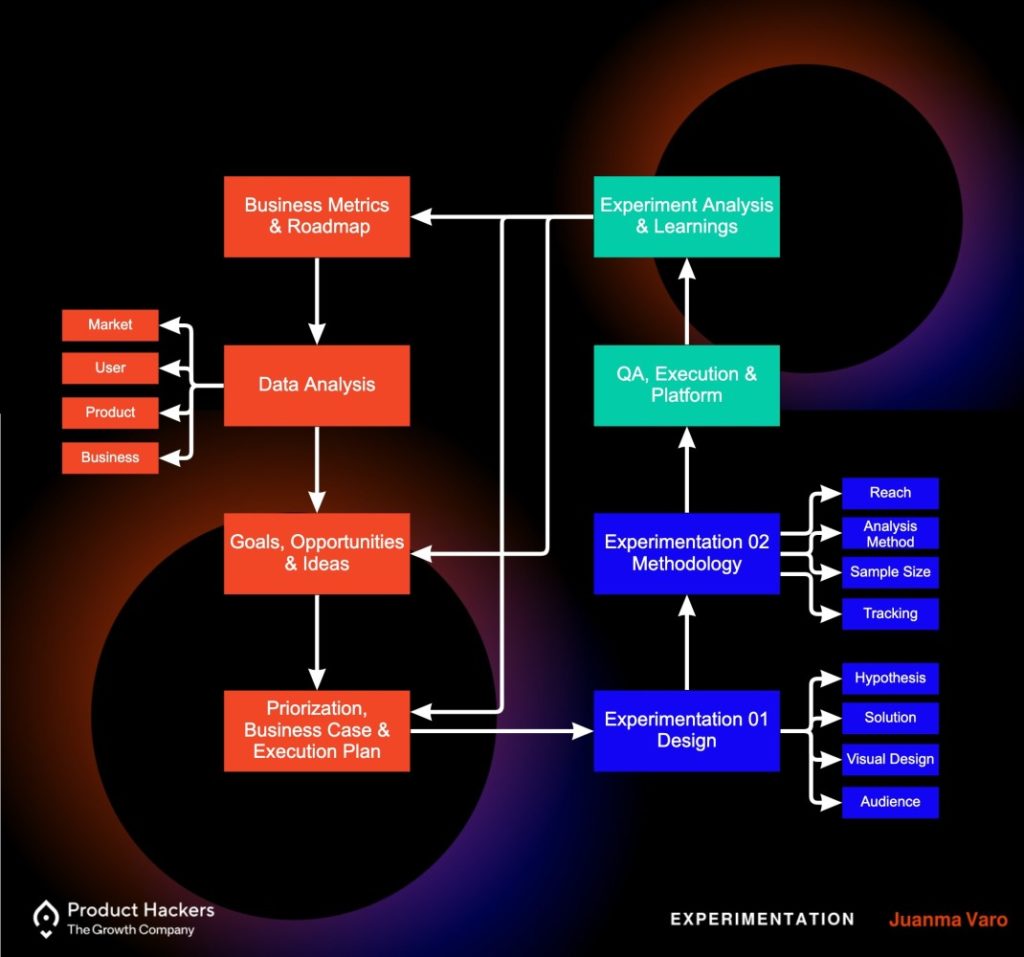
Pero en algún punto de este viaje sobre la experimentación, algo que suelo ver en los equipos es que, con el tiempo, la experimentación se adapta a una mala interpretación de sí misma que se resume en hacer A/B Testing; cuando A/B Testing es solo una metodología cuantitativa, como veríais en el gráfico Experimentation 02 -> Analysis Method.
No olvidemos que experimentamos para aprender, es decir, para hacer research, convirtiendo el delivery en el propio discovery.
Así que aquí aparecen tres preguntas clave:
Comparte en tus RRSS
Como ya conté en detalle estas metodologías en mi anterior artículo, solo voy a resumirlas a modo bullet point. Si quieres profundizar, o quejarte porque estoy dando volúmenes estimados sin tener en cuenta todas las dimensiones de un experimento, te invito a que, una vez acabes este artículo, te leas la anterior serie sobre experimentación (si todavía te quedan ganas). Así que abre este link en una nueva pestaña, por si acaso, todos lo hacemos.
Hacer A/B Testing no es barato, pero hacer A/B Testing mal hecho es carísimo e inútil. El número de conocimiento, personas involucradas y el nivel de precisión que se requiere para validar hipótesis no es algo que pueda hacerse de forma fácil y menos en cualquier equipo. Sobre todo porque el incorrecto análisis de datos nos puede llevar a que nuestros aprendizajes no valgan nada y que solo consumamos recursos para acabar tomando decisiones erróneas. Que por otra parte, es más común de lo que parece en la experimentación.
Por eso, además de tener un equipo con experiencia, también hay que valorar que de verdad esta es la metodología de análisis que queremos escoger. Este árbol de decisión es una forma aproximada muy ilustrativa de entender el proceso y las preguntas a seguir a la hora de tomar la decisión.
Consejo: nunca sigas ningún framework a ciegas. No dejes que el proceso tome todas las decisiones, sino que nos ayuden y guíen a tomarla. Nuestro criterio no debe ser sustituido, pero siempre debe someterse a presión.
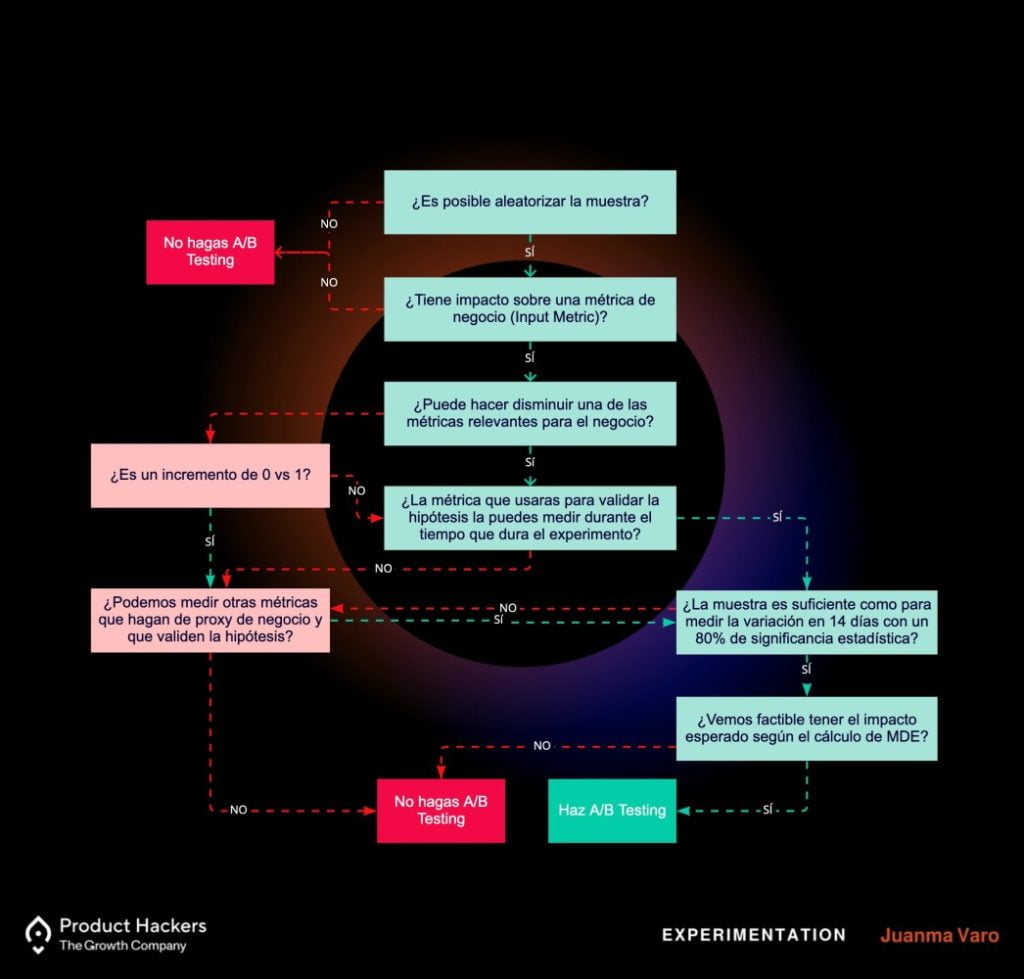
Ahora bien, resulta que después de haber navegado en nuestro árbol decisión, llegamos a un punto infinito donde la muestra no es suficiente como para medir la variación en 14 días con una significancia estadística de al menos un 80%, y buscamos métricas proxy más arriba del funnel que nuevamente no cumplen con el requisito (más adelante en el artículo explicaré en detalle esto de métricas proxy).
Dicho de otra forma: queremos usar A/B Testing como metodología de experimentación porque parte del objetivo es aprender y obtener experiencia en el equipo para cuando podamos hacerlo con más garantías. Pero según las calculadoras de muestra mínima necesitaríamos dejar correr el experimento por cientos de días, según la opinión de expertos y este propio artículo nos dicen que como mínimo necesitaremos 20.000 usuarios mensuales en una URL concreta, y el árbol de decisión nos dice que no podemos. ¿Nos rendimos aquí? Claro que no.
Lo primero que tenemos que hacer es definir «poco tráfico». Personalmente odio términos poco precisos como mucho, poco o bastante. La experimentación es ciencia, ¡dame un número!
Una página con poco tráfico es toda aquella que se sitúa entre los 100 y los 300 usuarios diarios en todo el sitio, es decir entre 3.000 y 9.000 visitas mensuales. Con menos de eso sí que vamos a estar obligados a ir a técnicas de User Testing como encuestas, entrevistas y screen recording a través de herramientas como Optimal Workshop, Hotjar o Sprig.
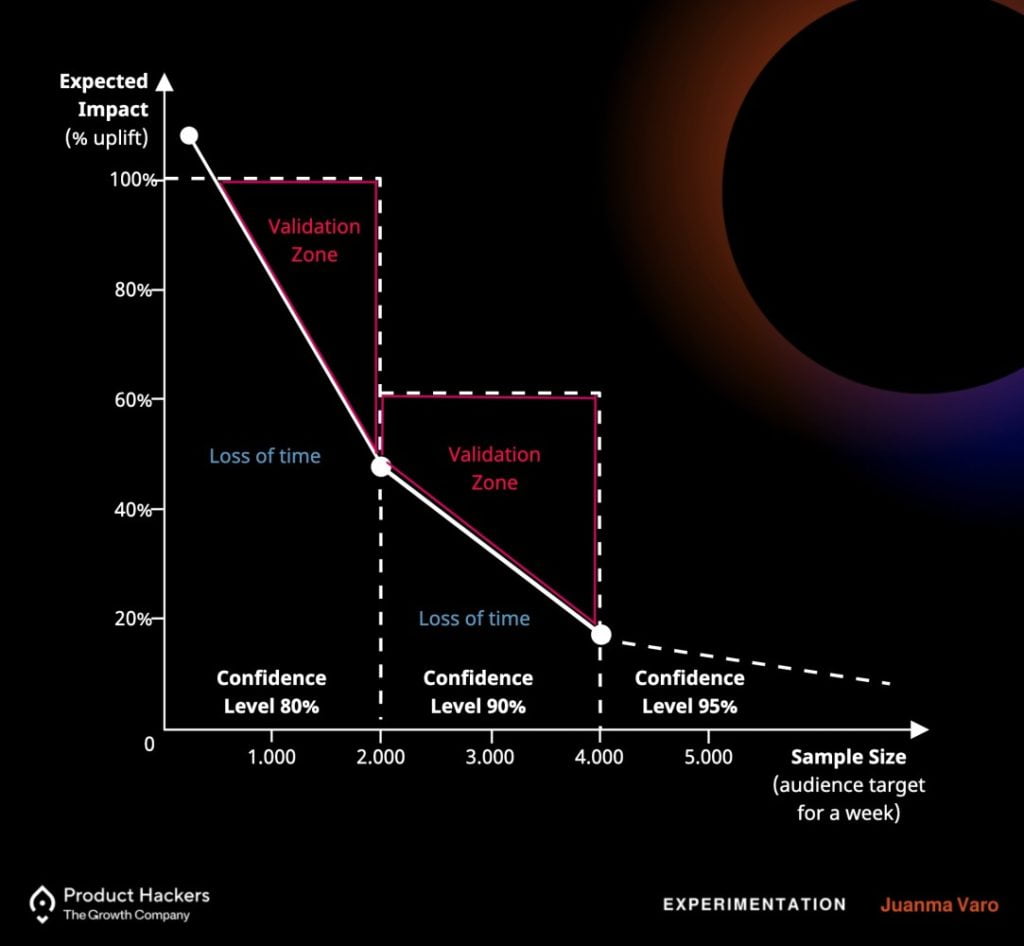
La siguiente gráfica ilustra muy bien tres de las cuatro dimensiones con las que debemos trabajar para poder realizar A/B Testing en sitios con poco tráfico:
Ahora que ya tenemos claros estos conceptos, veamos qué podemos hacer.
Los atributos claves de un A/B Testing siempre serán tiempo de duración, tamaño de la muestra y efecto esperado, y su propia fórmula matemática establece que cuanto mayor sea el MDE (efecto mínimo detectable) que esperamos ver en la variante, menos tiempo y menos muestra necesitamos para que los resultados obtenidos sean diferenciables del azar.
Por ello, cuando tenemos una muestra de usuarios pequeña y no queremos que nuestros experimentos estén corriendo durante años para obtener un resultado, necesitaremos un MDE alto, o dicho de otra forma, un impacto grande. ¿Y cómo obtenemos impactos más grandes? Generando hipótesis de un nivel superior a través de buscar problemas de usuario u oportunidades de negocio mayores. Aquí no nos vale con cambios de copy, imágenes o atacar a un sesgo cognitivo. Tenemos que pensar a lo grande.
Para verlo más claro, veamos varios ejemplos. Estos ejemplos no están basados en research de problemas y oportunidades ni en hipótesis reales, es solo una forma de ilustrarlo.

Esta es la home de Product Hackers Go!. A día de hoy es un sitio web con tráfico bajo, por lo tanto, proponer soluciones a problemas u oportunidades pequeñas, hará que planteemos soluciones pequeñas, que desemboca en diseños de experimentos con cambios pequeños, que a su vez, generará pequeñas diferencias en los resultados; lo que hará inútil el intento y estaremos realizando A/B Testing sin ningún sentido, más allá que el de consumir recursos.
Un ejemplo sería cambiar el copy del botón principal (CTA), para ver si el usuario es más susceptible al ahorro o al descubrimiento:
Si atacamos a un problema mayor, generaremos una hipótesis mayor, por ejemplo, validar que nuestro usuario se comporta de forma positiva a través de un nuevo customer journey que trata de enseñar al usuario el valor de la experimentación a través de un test y una serie de automatizaciones para generar engagement con la marca. La forma más rápida de validar esta hipótesis es a través de un chatbot.
Pero es posible que tampoco sea suficientemente grande. O que no seamos capaces de encontrar grandes problemas u oportunidades o de plantear soluciones de gran impacto, lo cual no es nada fácil. Para luchar contra eso, podemos generar una gran cantidad de cambios pequeños que tratan de validar muchas pequeñas hipótesis. La única desventaja aquí, como en el caso de cualquier A/B Testing en el que se hace más de un cambio, es que no sabremos qué ha motivado el cambio o si el cambio ha venido motivado por la suma de todos los cambios.
Es muy tentador probar todas las ideas que tenemos para resolver el mismo problema, y también es muy fácil que cada persona del equipo nos dé su feedback y, junto con él, un regalo en forma de nueva solución, un ligero cambio o un ligero añadido.
Pero con cada variante que añadimos, el tiempo para alcanzar la significancia estadística también aumenta, así que tenemos que escoger los mejores diseños. Y si tenemos poco tráfico, es más importante si cabe aprender a escogerlos bien para no quemar ninguna bala.
Aquí entra en juego el Usability Testing como compañero ideal del A/B Testing. Antes de lanzar las soluciones, primero usaremos esta metodología a través de herramientas como UsabilityHub, UserTesting o Maze; que nos permitirá validar diseños con usuarios reales antes de diseñarlos. De esta forma aseguramos el máximo impacto a la vez que conseguimos un gran ahorro de tiempo a la hora de diseñar, a la hora de ejecutar y a la hora de analizar.
Comparte en tus RRSS
Para tratar de simplificar la explicación, diremos que la significancia estadística es la probabilidad de que un evento que creemos que no es verdad, en realidad no lo es. Se hace en negativo porque no podemos asegurar que algo siempre pasará.
Por ejemplo: si dejo caer una pelota desde mi mano, ¿puedo asegurar que siempre que la deje caer se desplazará hacia el suelo por la fuerza de la gravedad? Según el método científico, no puedo confirmarlo porque no sabemos qué pasará en el futuro. Lo que sí puedo hacer es realizar una hipótesis nula (Ho): si dejo caer la pelota, no caerá. ¿Cómo de probable es que este evento no se produzca? Si tengo una certeza del 99,9% de que el no caer no se produce, estoy rechazando mi hipótesis nula con ese nivel de certeza. La certeza aumentará con el número de resultados que rechazan la hipótesis, a mayor número, mayor probabilidad.
Bien, si este ejemplo se te ha hecho demasiado denso, te aconsejo que pases al punto 4 directamente para que no abandones la lectura.
Después de esta aclaración, tenemos que entender que en el mundo digital el consenso general dictamina que para que un experimento sea válido, esa probabilidad de rechazar la hipótesis nula debe ser de al menos un 95%.
Para llegar a este nivel de seguridad necesitamos datos, muchos datos. Pero cuando no tenemos el lujo de tener grandes tamaños de muestra tenemos que descartar métodos tan estrictos y usarlos más bien como directrices que nos indica por dónde seguir.
Por ejemplo, al configurar la significancia estadística en un 80% hace que estemos dispuestos a aceptar que por cada 10 veces que se produce el efecto esperado, en 2 de ellos no estemos seguros de si fue por nuestro efecto o el azar. En otras palabras: por cada 10 resultados en los que creemos haber rechazado la hipótesis nula, puede que 2 solo se traten de falsos positivos. Pero con poco tráfico, podemos asumir más riesgo.
Tenemos que ser audaces para saber cuándo asumir riesgos en algunos tests y a aflojar las riendas del rigor estadístico en pos de mayor velocidad e impacto. Las startups se construyen sobre el riesgo, no sobre la seguridad. Que la ciencia sea un vehículo de ayuda, no una prisión.
No he tenido en cuenta la fuerza estadística, desviaciones estándar y otra serie de conceptos para simplificar la explicación y porque no son tan relevantes en sitios con poco tráfico. Del mismo modo, hay otros métodos que podríamos usar como t-sample test, chi-squared test, usar intervalos de confianza para un análisis de riesgo o mezclar la decisión de negocio con heurísticos y practical significance; pero el objetivo del artículo no es hablar sobre inferencia estadística. Si quieres saber más, te recomiendo el blog Towards Data Science.
Otro enfoque que disminuye la confianza y aumenta la muestra está en usar como métrica de medición sesiones en lugar de usuarios (como hace Google Optimize, el software gratuito recomendado para que sea tu puerta de entrada al mundo del A/B Testing). Esto significa que el experimento no trata a cada usuario como un participante, sino que será cada sesión la que cuente como un participante de la muestra.
Esto incluirá a los usuarios que visiten el experimento dos o más veces, reduciendo el tiempo y la muestra de usuarios únicos necesaria. Este enfoque es más apropiado para experimentos que sólo tienen un impacto en el comportamiento de un usuario dentro de una sola sesión en lugar de su experiencia completa en el sitio. Por lo tanto, algunos de esos grandes cambios que comentamos en el punto 1 pueden no ser aplicables en este escenario.
Volvamos a nuestro ejemplo anterior, si queremos validar los experimentos realizados en Product Hackers Go! con métricas clave como el número de suscripciones, es muy probable que nuestro volumen de conversiones sea tan bajo que nuestros cálculos de MDE nos dirá que no vamos a ser capaces de diferenciarlo del azar. Ni siquiera disminuyendo el umbral de significancia estadística como hemos visto en el punto anterior.
Los datos de tráfico y conversiones semanales son ficticios, pero el resto de cálculos los procesa directamente esta calculadora:
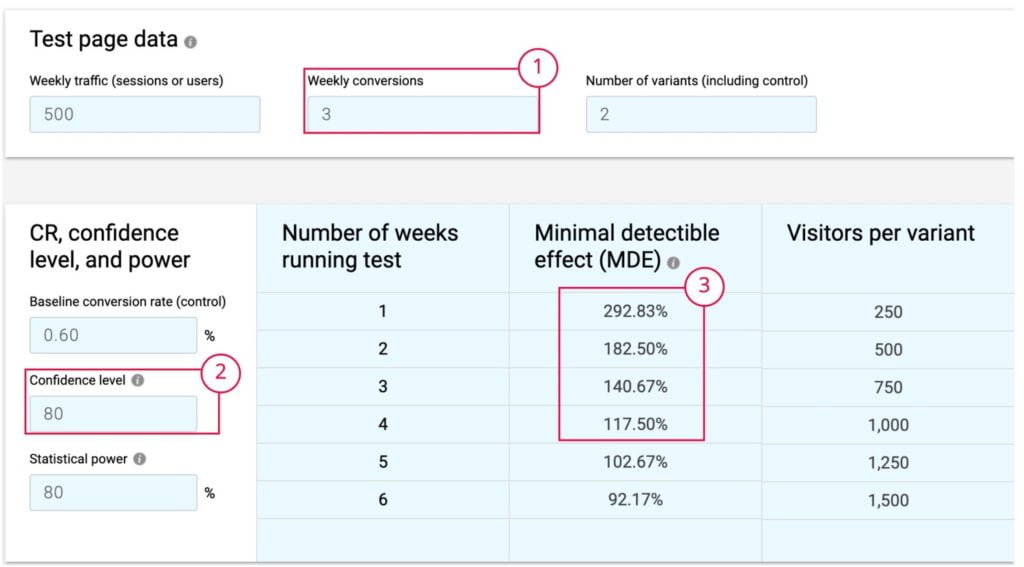
Aquí vemos lo siguiente:
El ratio de conversion se convierte en la cuarta dimensión que habíamos visto antes y que nos permite tener ya una visión completa de nuestra capacidad de realizar A/B Testing. Cuanto más alta sea esta tasa de conversión, menos tiempo necesitará para alcanzar la significancia estadística.
Por lo tanto, cuanto más cerca de la conversión clave que buscamos, o más abajo en el funnel, más bajo será el ratio y más usuarios y tiempo necesitaremos. Mayor tiempo también significa altas probabilidades de contaminación de datos y, por tanto, que los datos a analizar no nos sirvan. Así que si queremos realizar A/B Testing, tendremos que buscar una serie de métricas que hagan de proxy y que nos permita validar hipótesis.
Volvamos ahora a qué ocurriría en nuestro experimento en Product Hackers Go! si creamos un chatbot cuya métrica proxy es la conversión a captura de leads:
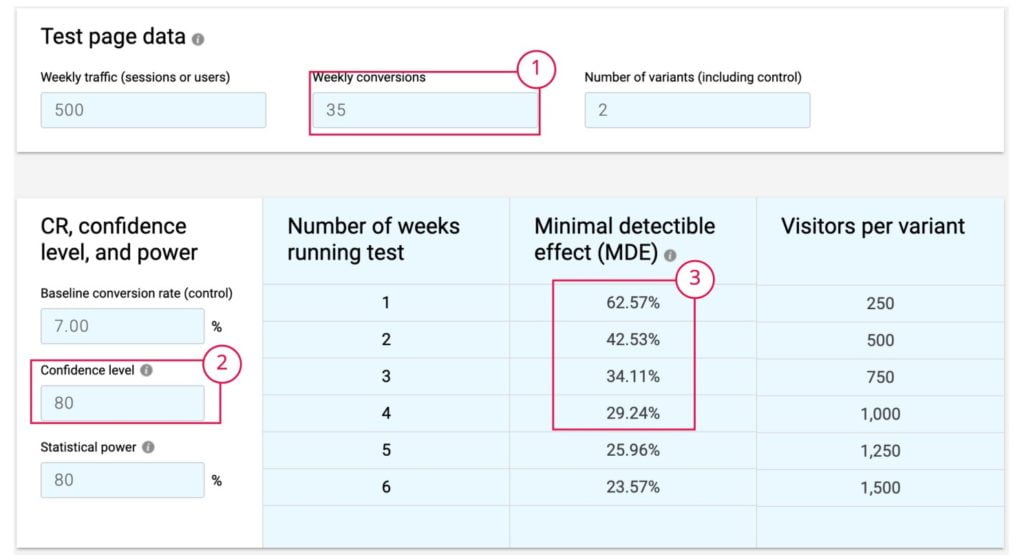
En el ejemplo, la captación de leads semanales son 35, siendo un conversion rate de un 7%. Esto nos dice que manteniendo el umbral de significancia estadística a un 80% podríamos ver resultados en 2 semanas si conseguimos aumentar la conversión un 43%, es decir pasar de obtener 35 leads semanales a 50. Aunque recordemos que con este nivel de significancia estadística, de esos 50 leads, 10 pueden ser falsos positivos (realmente, realizando cálculos precisos la probabilidad es de 16,6%, es decir: 8. Aquí otra calculadora que te ayuda a medirlo).
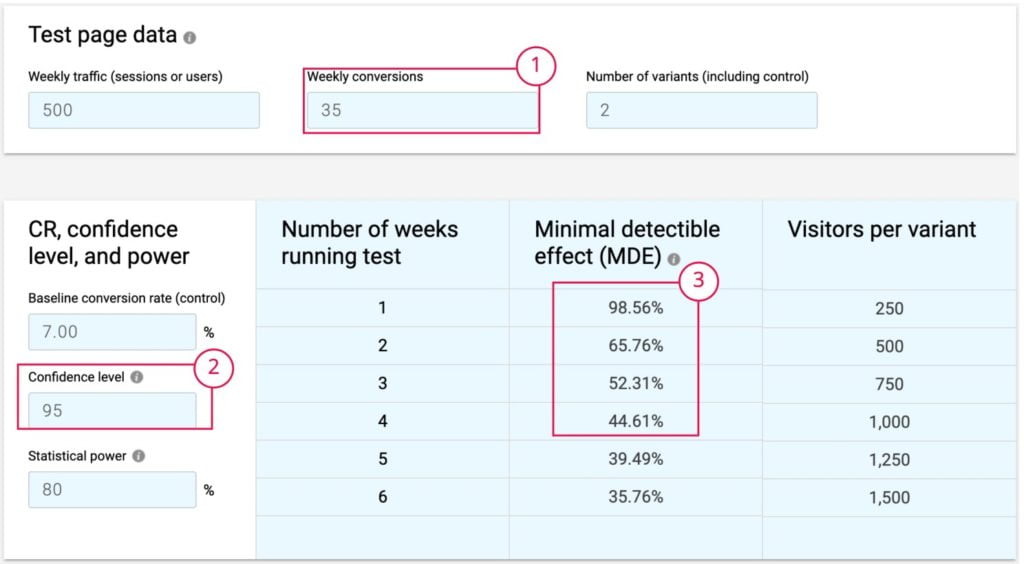
Si el experimento conlleva riesgo y queremos tener mayor seguridad y aumentar nuestro umbral de significancia estadística al 95%, para poder validarlo, necesitaríamos pasar de 35 leads semanales a 58, donde disminuimos la probabilidad de falsos positivos a 3.
Sabiendo nuestra tasa de incremento, ahora deberíamos calcular, si no lo tenemos ya, cuál es el conversión desde lead a compra sobre un periodo de tiempo. Digamos que es de 4 meses, por lo tanto podríamos proyectar el impacto esperado en el futuro. Aunque cuanto más nos alejamos de las observaciones reales, más probabilidad de que nuestra proyección no sea certera.
Experimentar ≠ A/B Testing
Growth ≠ Experimentar
En realizar este artículo sobre experimentación he dedicado más o menos unas 14 horas, sin contar los años que he tardado en conseguir la experiencia suficiente como para explicarlo. Si quieres contribuir de alguna forma a que siga escribiendo contenido técnico sobre growth y experimentación, tan solo tienes que dejar un comentario o compartirlo con aquellas personas a las que crees que le puede resultar de ayuda.
Gracias por leer sobre experimentación.







Oro puro!! Ojalá haber encontrado esto antes. Enhorabuena por el currazo. 🚀🚀🚀
Master class! Gracias!
Excelente contenido. Gracias por compartir!!!
Expones una visión muy amplia y sobre todo muy acertada sobre el AB testing el cual creo que está sobrevalorado en experimentación ( de acuerdo al rigor que implica, el tiempo, el esfuerzo, etc). De acuerdo al estadío de la empresa y el fenómeno analizado, etc, valoro mucho la aproximación que dan métodos más cuali/ cuanti de investigación en ambientes más controlados sobre prototipos, aunque se llegue a menor numero de muestra.
Saludos.